
Part 1: Signals are vectors #
It’s like 12:30AM right now and I cant sleep so time to bang out one of those late night rants to procrastinate actual work I should be doing. So there’s this one thing that annoys me about signal processing education in many universities. There is some very unified and beautiful language that you can use to understand how some of the least understood concepts in signal processing work that are core to the field: frequency transforms. Fourier transforms, Laplace transforms, Z transforms, what have yous.
The language of linear algebra basically describes many of the core ideas in signal processing extremely well and help you understand how the concepts behave and interact, and it’s the same concepts that you learn in an undergraduate linear algebra class, which is why it is extremely frustrating for me when I realise that only a small minority of signal processing courses are taking advantage of the rich background that many students already have to explain some enlightening new concepts.
Note: In this post, I’ve used the word function instead of signal but I make a point to use f(t) anyway because I’m approaching this from a signal processing point of view.
Vectors and linear transformations #
Note: If you are comfortable with the intuition of linear algebra, this is likely superfluous for you. If you are not, this is provided as a quick reference. If you would like to build stronger intuition, I strongly recommend 3blue1brown’s Essence to Linear algebra series
A vector is some geometric object that we can think about as a magnitude with a particular direction. This abstract object can be represented in a particular coordinate system and this results in an array of numbers that represent the scaling of individual basis vectors. That is, when we have a vector
$$ \vec x = \begin{bmatrix} 2 \\ 3 \\ 4 \end{bmatrix} $$
We’re saying the vector (\vec{x}) is equal to a weighted sum of three basis vectors, \( 2\vec e_1 + 3\vec e_2 + 4\vec e_3 \). We can rewrite this vector in different coordinate systems also, in which case the coefficients in front of the basis vectors \( \vec e_i \) would be different numbers.
Along with the concept of vectors comes the ideas of linear transformations. Linear transformations are abstract transformation (a mapping) of a vector space that matches conditions for linearity. In a particular basis, this is represented with a matrix.
A transformation is linear if for any two vectors, when you send two different vectors through the transformation and add their outputs together, the result is the same as adding the two input vectors and sending it through the transformation. This is obeying the principle of superposition, a linear transformation \(A\) such that $$A(\vec{x} + \vec{y}) = A\vec{x} + A\vec{y}$$ and homogeniety, or $$A(c\vec{x}) = c(A\vec{x})$$
Now vectors and matrices are very cool but you can do some very cool operations on them also. For example, the dot product is a simple operation. If you have two vectors, their dot product corresponds to the length of one vector if it were projected down to the other vector and multiplied by length of that other vector. See the diagram below:
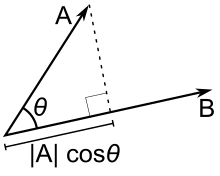
This is what the dot product means, but you still need to calculate it. To calculate it when the vectors are written in a particular basis, you multiply them element-wise (i.e. you take each corresponding element and multiply them) and sum them. $$ \vec{x} \cdot \vec{y} = \sum_{i=1}^{N} \vec{x}_i \vec{y}_i$$ A cool thing about the dot product is that when you take the dot product of a vector with itself, you essentially find the length of your vector projected to itself (which is the same vector), multiplied by the length of your vector. Hence the square root of a dot product of a vector with itself gives the length of that vector.
$$||\vec x|| = \sqrt{\vec x \cdot \vec x}$$
Because of the projection nature of dot products, you also get the particular situation where if two vectors are orthogonal, AKA they are at right angles to each other, AKA there is no component of one in the direction of the other, then their dot product is \( \vec x \cdot \vec y = 0 \).
$$ \vec x \cdot \vec y = 0 \implies \vec x \perp \vec y $$
If you want to represent a vector in a basis, as a sum of different basis vectors, you can do that using dot products. For example, if you have a set of new basis vectors \({\vec e_i}\), and they are orthogonal to each other, then you can project your vector to that basis vector to find the contribution. This can be done with a dot product, although one needs to scale down by the basis vector’s length to get the true projection.
$$ \vec x = \sum_{i=0}^N \text{proj}_{\vec e_i} \vec x $$
$$ = \sum_{i=0}^N \vec x \cdot \frac{\vec{e_i}}{||\vec e_i||} = \sum_{i=0}^N \vec x \cdot \frac{\vec e_i}{\sqrt{\vec e_i\cdot \vec e_i}} $$
Of course \(\vec e_i\) are unit length (AKA normalised), the bottom part becomes \(1\) and doesnt need to be added.
Abstract linear algebra #
Now this is where it gets a bit more… creative? I have already been talking about vectors and such a bit carefully, pointing out that arrays of numbers are not vectors, but representations of vectors in a particular basis. This vector is an abstract geometric object beyond just a list of numbers. However there is an even more abstract idea of a vector that I believe many linear algebra courses avoid talking about properly, especially those in more applied and “practical” institutions.
What if we were able to boil down the essence of what it means to be a vector? Find all the necessary first-principle properties that make any kind of object behave like a vector and how we expect it to behave. You could find those minimum properties, and see if things other than what we traditionally think of as vectors share them. If you do that, you get a mathematician’s definition of a vector space. To a mathematician, a vector is member of any set of objects such that they follow a set of “axioms” or principle requirements for the behaviour of vectors to emerge.
For example, they must be able to be added together and multiplied by scalars, and they must also associate during addition \(\vec u + (\vec v + \vec w) = (\vec u + \vec v) + \vec w\), and have a \(\vec 0\) vector (a vector such that when added doesnt change the vector it’s added to), must have a “negative” or inverse of a vector, and so on. There’s a few more axioms like this, and together they define the minimum conditions needed for something to behave like a vector as we know it.
The basic vector space axioms dont include further operations or any particular definition of length etc; those have their own further axioms as extensions. But we can extend those to general abstract vectors too. For example, there is an equivalent to the dot product we know and love from normal linear algebra. Here to distinguish it from the normal dot product we give it different notation and name. We call it the inner product instead and we write it as \(\langle \vec x, \vec y \rangle\) instead of \(\vec x \cdot \vec y\).
Functions as vectors #
Okay, that is nice and all but how does that apply for us here. Well, it just so turns out that functions are vectors! If you want, you can go around and prove the vector space axioms for functions yourself, but we’re going to take that for granted.
Looking at it in a more numerical way, you can think of how arrays are essentially a mapping between a discrete index \(i\) and to a basis coefficient \(\vec v_i\), is a representation of that. Well, if you look at a function, say \(f(t)\), it is essentially a mapping between a continuous index \(t\) and a basis coefficient \(f(t)\). That’s one way to think about functions as vectors; instead of having finite dimensions, usually indexed by \(i\), you have an infinite dimensional vector where the indexing is continuous. Using this fact, you can implement all your vector operations.
For example, for finite dimensional vectors, you can add two of them by adding the values at each index. Functions work the same, just with your index being infinite dimensional. Scalar multiplication? Also easy! Just multiply the value at each index.
$$ \vec f + \vec g = f(t) + g(t) $$
$$ a \vec f = a\ f(t)$$
There’s some things that aren’t totally obvious, make a lot of sense when you point them out. How do you take the dot product, or rather, inner product, of two functions? Well, let’s look at the standard dot product: you multiply the two values at matching indices, and then you sum over all indices. Well, you can do the same thing with functions! Although, we now have a continuous index, so we’ll have to change out that \(\sum\) for an integral. Using this, we get
$$\langle f(t), g(t) \rangle = \int_a^b f(t) g(t) , dt$$
Here we’ll note that a space of functions is only defined over a domain so we need to specify integral bounds, even if it’s \((-\infty, \infty)\). But how cool is that! We can now forget that functions are… well, functions! We can think about vectors. And defining an “inner product” is actually really powerful, because we can now use it to define things like the “length” of a function, or the “distance” between two functions. For example, the length of function vector \(f(t)\) is
$$ ||f(t)|| = \sqrt{\langle f(t), f(t) \rangle} = \int_a^b f(t)^2 , dt$$
And you can use that to define the distance between two functions as \(||f(t)-g(t)||\). Not only that, but you can come up with interesting generalised concepts! A really important one for us is orthogonality. If the inner product between two functions is \(0\), then they are orthogonal to each other.
$$\langle f(t), g(t) \rangle = \int_a^b f(t) g(t) \ dt = 0 \\ \implies \vec f \perp \vec g$$
Aaand that’s enough for Part 1. In Part 2, I discuss how to extend on the idea of signals/functions being vectors with the idea of systems being “maps” between vectors.